【艺恩观察】具身智能的胜负手,是一台转起来的「数据飞轮」
核心摘要
当大模型在文本世界里逼近天花板,下一个被反复提起的词,是「具身智能」。但很少有人点破:机器人能否迎来自己的「GPT 时刻」,瓶颈不在算法,而在数据。更准确地说,在于能否搭起一台持续转动的「数据飞轮」。
白皮书把这台飞轮的逻辑讲得很清楚:「交互→数据→模型改进」的闭环,正成为最难复制的护城河。谁先让飞轮转起来,谁就能在数据、能力、场景之间形成正反馈——而这,远比一时的算法领先更难被追赶。
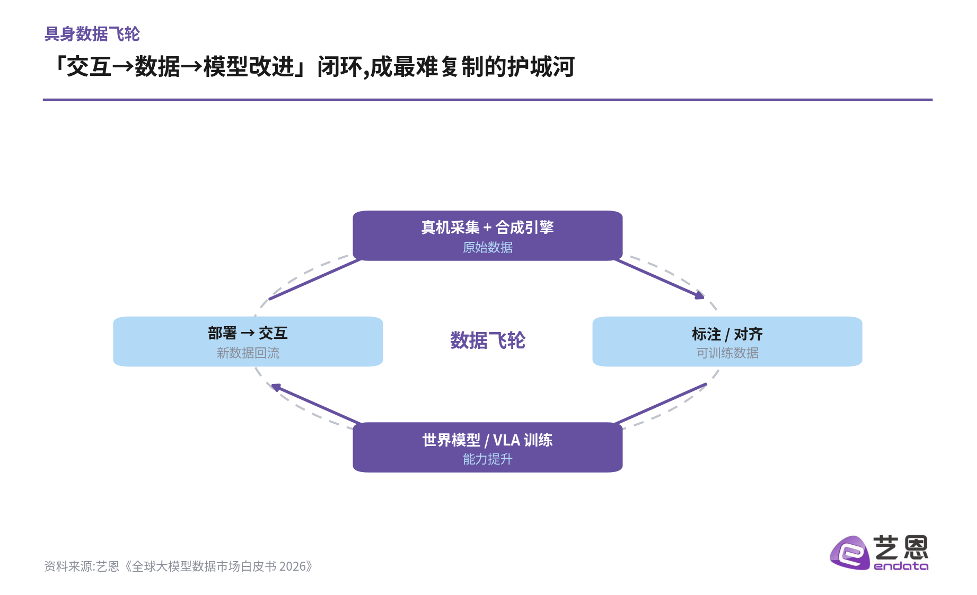
图 1|「交互→数据→模型改进」闭环,成最难复制的护城河
飞轮的四个环节环环相扣:真机采集与合成引擎产出原始数据,标注与对齐把它变成可训练数据,世界模型与VLA训练带来能力提升,部署到真实场景后产生交互、又把新数据回流。一旦这个循环跑顺,数据会越滚越多、模型会越用越强——这正是「数据飞轮」作为护城河的真正含义。
这套逻辑并不新鲜——它正是大模型在文本世界跑通的剧本:模型用得越多,产生的交互数据越多,反过来又让模型更强。区别在于,具身世界的「交互」发生在物理空间,数据的采集、对齐与回流都要难得多。也正因为难,一旦跑通,壁垒也更高、更难被复制。
但飞轮难启动:具身数据的「三难」
问题在于,这台飞轮极难启动。具身数据有「三难」:稀缺、采集困难、高维。世界模型面临「配对多视角数据严重稀缺」,而具身数据本身又难采集、维度极高——这三重困难叠加,被普遍视为机器人达到「GPT 时刻」的关键瓶颈。

图 2|具身数据「稀缺、采集困难、高维」是机器人的关键瓶颈
与文本不同,具身数据无法靠爬虫批量获取:它需要真实机器人在物理世界里一次次试错,或在高保真仿真中大规模生成,再配上精确的多视角、力反馈与时序标注。每一条高质量数据,背后都是真金白银的采集与标注成本。
更麻烦的是,具身数据高度「长尾」:真实世界里的物体、场景、动作组合近乎无穷,任何单一数据集都难以覆盖。这也是为什么,行业普遍认为单靠真机采集无法解决问题——必须叠加合成,才能在成本可控的前提下,尽可能逼近这条长尾。
艺恩观察
具身数据的稀缺,和专家数据同源:都「买不到现成的」。这也决定了,具身智能的竞争,从一开始就是一场围绕「数据生产能力」的竞争,而非单纯的算法竞赛。
中国进展:一个被误传的数字,与真实的量级
中国在具身数据上的推进值得关注,但传播中也出现了误读。合成灵巧抓取数据集DexGraspNet 2.0(CoRL 2024)常被误传为「10 亿规模」;按论文口径,它实际包含约1319个物体、8270 个场景、4.27 亿条抓取标注。量级依然可观,但与「10 亿」相差一个数量级——在面向专业读者的传播里,这种数字的严谨至关重要。
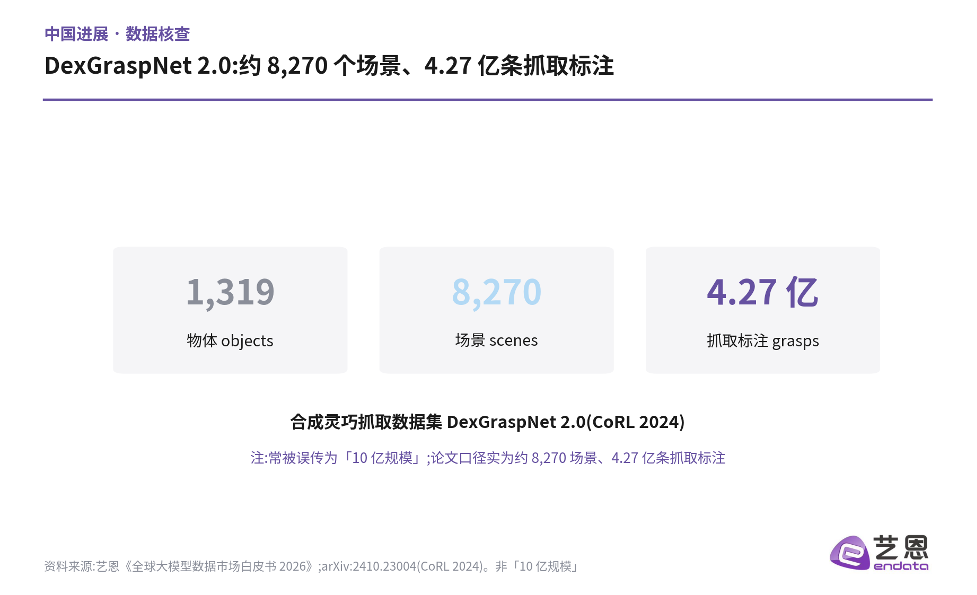
图 3|DexGraspNet 2.0:约8270个场景、4.27亿条抓取标注(非「10 亿规模」)
数字的严谨之所以重要,是因为具身赛道仍处早期,任何被夸大的「规模神话」,都可能误导对技术成熟度的判断。约4.27亿条抓取标注已是相当可观的工程成就;把它说成「10 亿」,既无必要,也会损害面向专业读者的可信度。
除了合成数据集,产业侧也在加速。据信通院,头部具身公司已部署百台机器人,日产真机数据上万条。一边是仿真合成的规模化产能,一边是真机采集的高质量样本——两条腿走路,正是中国具身数据供应链逐步成型的标志。
这条供应链的成型意义重大:它意味着机器人公司不必每家都从零自建数据能力,而可以依托专业的数据供给方,更快地把飞轮转起来。分工一旦出现,整条产业的迭代速度都会被抬升——这与互联网时代「云厂商托底算力」的分工逻辑如出一辙。
路径:从「真机采集」到「合成+真机精调」
如何破解「三难」?路径正从「真机采集」走向「合成引擎+真机精调」:用合成引擎解决规模与成本,用真机精调校准质量与物理一致性。这与文本世界「合成+真实精调」的混合配方异曲同工——合成解决「有没有」,真实解决「对不对」。

图 4|供给路径正从「真机采集」走向「合成引擎+真机精调」
这条混合路径,也重新定义了具身数据供给方的价值:不是比谁采得多,而是比谁能把「合成产能」与「真机质量」高效拼接,并保证标注精度、物理一致性与合规可溯源。能做到这一点的玩家,才真正握住了飞轮的「第一推动力」。
从投资视角看,这条路径还重塑了成本结构:前期靠仿真大规模铺量、摊薄边际成本,后期靠少量高质量真机数据做精调、抬升能力上限。能把这两段成本曲线衔接好的公司,既跑得快,又烧得省——这正是资本在具身数据赛道最看重的效率。
对行业与投资者的含义
对机器人公司:数据飞轮的启动速度,可能比单点算法更决定终局;尽早搭建「真机+合成」的数据基础设施,是把未来训练成本前置摊薄的关键。
对数据供给方:具身/4D多模态是价值链最稀缺的前沿之一,谁能稳定供给高质量、合规、富标注的具身数据,谁就站在了最高溢价的位置。
对投资者:评估具身赛道,除了看本体与算法,更要看「数据飞轮」是否成型——数据的可持续供给,是穿越长周期的硬指标。
这也解释了资本对具身赛道为何既热情又谨慎:热情,是因为数据飞轮一旦转起来,护城河极深;谨慎,是因为飞轮启动期漫长、烧钱,且高度依赖数据基础设施的扎实程度。看懂飞轮,才能既不错过机会,也不高估短期进度。
把镜头拉远,具身数据飞轮的意义不止于机器人本身。世界模型既消耗数据,也能生成未来训练所需的合成数据——它既是数据的「消费者」,也是「生产者」。一旦这层飞轮转起来,它会反哺整个数据产业,成为继文本、视频之后的又一个增长极。
机器人的「GPT 时刻」,不会由某一个聪明的模型单独触发,而会由一台转得足够快的数据飞轮推动到来。在那之前,谁掌握稀缺、合规、可训练的具身数据,谁就掌握了入场券。
-全文完 · 数据来源见文中标注-


所有文章未经授权禁止转载、摘编、复制或建立镜像,违规转载法律必究。
举报邮箱:1002263188@qq.com

